
Voice & Speech
Picovoice
oice AI platform for on-device speech recognition and wake words
Freemium
★★★★½
4.7
Wake Word Detection
Speech Recognition
Voice AI
Edge AI
Speaker Recognition
Offline Voice Processing
Developer Tools
IoT Voice
About Picovoice
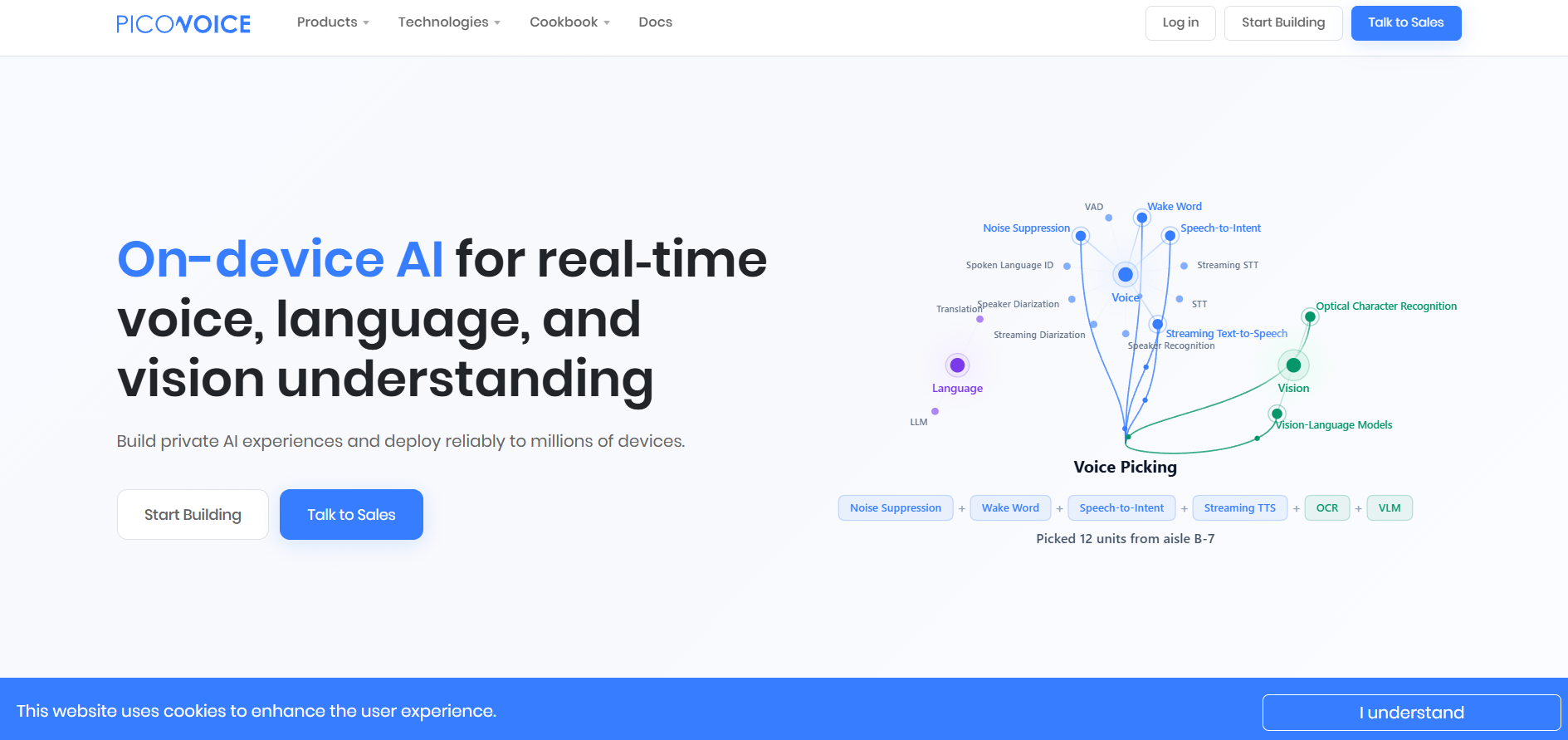
Picovoice is a voice AI platform with a distinctive engineering philosophy: everything runs on-device. Wake words, speech-to-text, intent understanding and voice commands execute locally on phones, browsers, Raspberry Pis and microcontrollers — no audio ever travels to a cloud.
The platform is a suite of focused engines: Porcupine (custom wake words like "Hey Jarvis"), Leopard/Cheetah (speech-to-text, batch and streaming), Rhino (speech-to-intent for commands), Eagle (speaker recognition) and more. A web console lets you train custom wake words and command models in minutes, then deploy the same models across platforms from web to embedded.
Pricing: a free tier suits makers and evaluation; commercial plans license by usage.
Strengths: privacy by architecture (nothing leaves the device), zero network latency, offline reliability, and tiny footprints that run on microcontrollers — a category cloud APIs can't touch. Weaknesses: on-device models trade some accuracy versus giant cloud models for open-ended dictation; it's a developer SDK, not an end-user app; and complex free-form conversations still favor cloud LLM stacks.
Who it's for: developers building voice into products where privacy, latency, offline operation or hardware constraints matter — smart devices, cars, appliances, kiosks and mobile apps.
The platform is a suite of focused engines: Porcupine (custom wake words like "Hey Jarvis"), Leopard/Cheetah (speech-to-text, batch and streaming), Rhino (speech-to-intent for commands), Eagle (speaker recognition) and more. A web console lets you train custom wake words and command models in minutes, then deploy the same models across platforms from web to embedded.
Pricing: a free tier suits makers and evaluation; commercial plans license by usage.
Strengths: privacy by architecture (nothing leaves the device), zero network latency, offline reliability, and tiny footprints that run on microcontrollers — a category cloud APIs can't touch. Weaknesses: on-device models trade some accuracy versus giant cloud models for open-ended dictation; it's a developer SDK, not an end-user app; and complex free-form conversations still favor cloud LLM stacks.
Who it's for: developers building voice into products where privacy, latency, offline operation or hardware constraints matter — smart devices, cars, appliances, kiosks and mobile apps.
Frequently Asked Questions
What is Picovoice and how does its architecture differ from cloud-based alternatives?
Picovoice is an edge-first voice AI platform engineered to process all acoustic and speech data directly on the host hardware rather than streaming audio to a centralized cloud. Because inference occurs entirely on-device, applications built with the platform suffer zero network latency, save significantly on recurring data transfer costs, and remain completely operational without an internet connection. This decentralized design ensures natural, localized user privacy compliance under frameworks like HIPAA and GDPR.
What specific machine learning engines are available in the Picovoice voice stack?
The platform supplies developers with a modular suite of highly optimized, tiny machine learning models designed to handle individual components of an acoustic interaction pipeline:
Porcupine: An ultra-lightweight wake word engine for always-on keyword spotting that uses minimal processor overhead to trigger applications.
Rhino: A localized Speech-to-Intent engine that extracts structured semantic meaning directly from spoken commands within a specified context without needing full transcription.
Leopard & Cheetah: Compact speech-to-text engines built for offline batch transcription and live audio streaming, respectively.
Orca & Eagle: Highly efficient, on-device text-to-speech synthesis and biometrically secure speaker recognition systems.
Porcupine: An ultra-lightweight wake word engine for always-on keyword spotting that uses minimal processor overhead to trigger applications.
Rhino: A localized Speech-to-Intent engine that extracts structured semantic meaning directly from spoken commands within a specified context without needing full transcription.
Leopard & Cheetah: Compact speech-to-text engines built for offline batch transcription and live audio streaming, respectively.
Orca & Eagle: Highly efficient, on-device text-to-speech synthesis and biometrically secure speaker recognition systems.
How does the type-to-train developer console accelerate production timelines?
The self-service Picovoice Developer Console completely bypasses traditional machine learning roadblocks like gathering training audio data, configuring neural network architectures, or provisioning heavy GPU clusters. Using a web interface, product managers or developers can simply type in their desired branded wake word or targeted command parameters textually. The underlying platform trains, compresses, and compiles a production-ready model binary file optimized for their chosen hardware platform within seconds.
What hardware ecosystems and programming environments does Picovoice natively support?
Designed to achieve cross-platform consistency, the software engines compile cleanly across highly diverse processing architectures. The platform supports ultra-low-power microcontrollers (including ARM Cortex-M, STM32, and Arduino boards), single-board systems like the Raspberry Pi, standard mobile setups (iOS and Android), and web browsers via WebAssembly. Software engineering teams can rapidly integrate these edge models using native SDK wrappers for React Native, Flutter, Python, Node.js, Java, .NET, and C.
What does "on-device" mean for Picovoice?
All voice processing happens locally on your hardware — audio never goes to a server. That means privacy, offline operation and instant response.
Is Picovoice free?
A free tier covers personal projects and evaluation; commercial deployments use paid licensing.
Q: Can I make a cu
Q: Can I make a cu
Can I make a custom wake word?
Yes — Porcupine lets you train custom wake words ("Hey MyProduct") in the console within minutes, no ML expertise needed.
Picovoice vs cloud speech APIs?
Cloud wins for open-ended dictation accuracy; Picovoice wins for privacy, latency, offline use and running on tiny hardware.
Similar Tools
More in Voice & Speech

Auphonic
Voice & Speech
AI audio post-production tool for leveling, noise reduction, and encoding.
🎙️
PaidElevenLabs
Voice & Speech
Ultra-realistic text-to-speech and voice cloning.

Sonix
Voice & Speech
AI transcription platform for audio-to-text conversion

Transkriptor
Voice & Speech
Effortlessly transcribe audio to accurate text across 100+ languages.
📬 The 5 best new AI tools, every Tuesday
One short email. No spam, unsubscribe anytime.